Paper Autumn: Origami style autumn-themed effect
项目时间 Date
2024.9
项目类型 Project type
AI 设计 AI Design
完成人 Author
倪威 ARJANE
关键词 Keyword
Lora 训练 Lora training, 训练日志 Training log, 工作流介绍 Workflow
秋天到了,试试这个温暖、令人心安的AI折纸特效吧。
Autumn is here. Try this warm and comforting origami art AI Lens.

我将会介绍这个模型的训练过程和 ComfyUI 工作流搭建思路。
I will introduce the training process of this model and the ComfyUI workflow.
数据集处理 Dataset Preparation
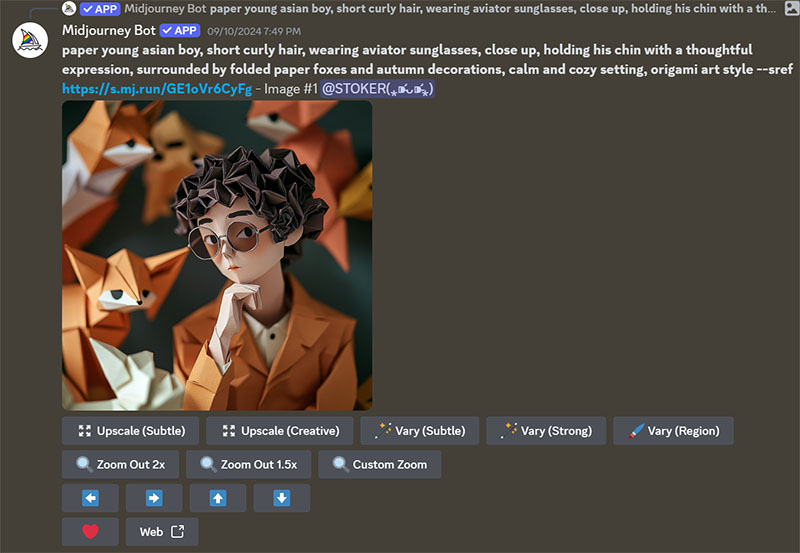
所有用到的数据都是 Midjourney 的合成图像。具体而言,我从搜索引擎上找了一张折纸艺术的图,利用 style reference,然后加上一些关于秋天的提示词,生成了最初的几张图片。
All the data used are composite images from Midjourney. Specifically, I used an origami art picture from search engine as style reference, added some autumn-related prompts for the few generations.
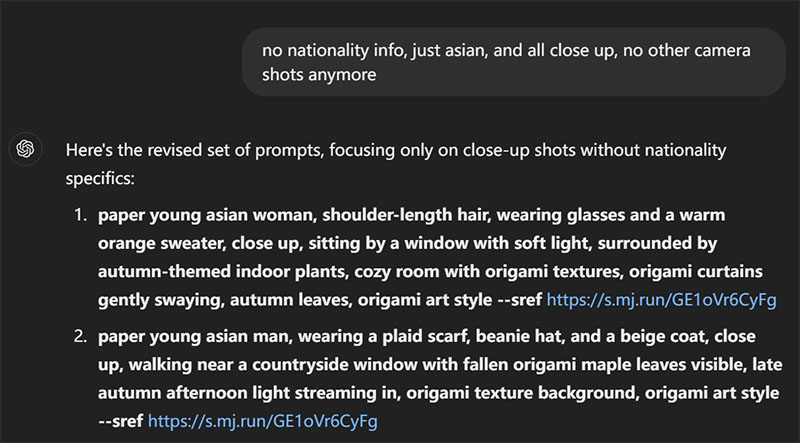
一个重要的问题是提示词的多样性。我没办法围绕折纸艺术和秋天写几十上百个提示词,所以…ChatGPT,启动!
A big barrier is the variety of prompts. I had no creativity to write dozens or hundreds of prompts about origami and autumn, so… ChatGPT, time for the show!
剩下的工作就简单了, 利用打标工具对图片进行标注即可。本项目里我用的是gpt-4o。
The rest of the work is simple, just use caption tools to create tags for images. In this project, I used gpt-4o.
模型训练 LoRA Training
SDXL Base v1.0 被用作底模。根据我的经验,使用 SDXL 基座模型作为底模在色彩、稳定性、泛用性方面比其下游模型更出色,特别是各类 SDXL Mix 模型。
SDXL Base v1.0 was used as the base model. In my experience, SDXL base is always better than its downstream models in terms of color, stability, and versatility for LoRA training, especially way better than the various SDXL Mix models.
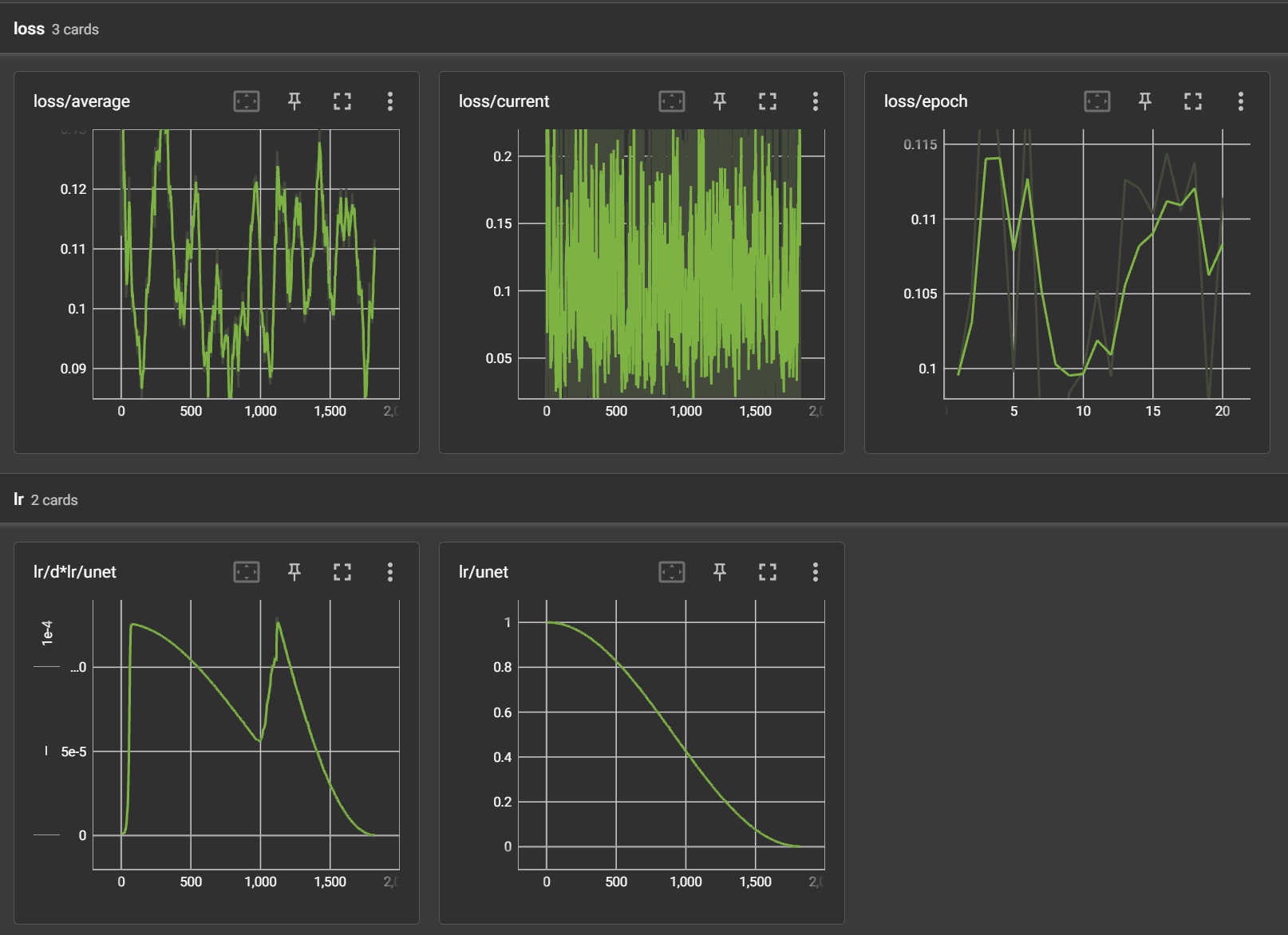
我使用了 Prodigy 优化器,这是一款自适应学习率的优化器,因此我不用过多操心学习率的问题。SDXL LoRA 训练中,损失值非常没有参考意义,例如这次训练中,从头到尾损失值都没有明显下降,曲线非常难看,我也不懂这是为什么。
I used the Prodigy optimizer, which is an adaptive learning rate optimizer, so I didn’t have to worry too much about the learning rate. In SDXL LoRA training, the loss value is very meaningless. For example, in this training, the loss value did not drop significantly from the beginning to the end, the curve graph seems terrible, and I don’t understand why.

工作流搭建 ComfyUI Workflow
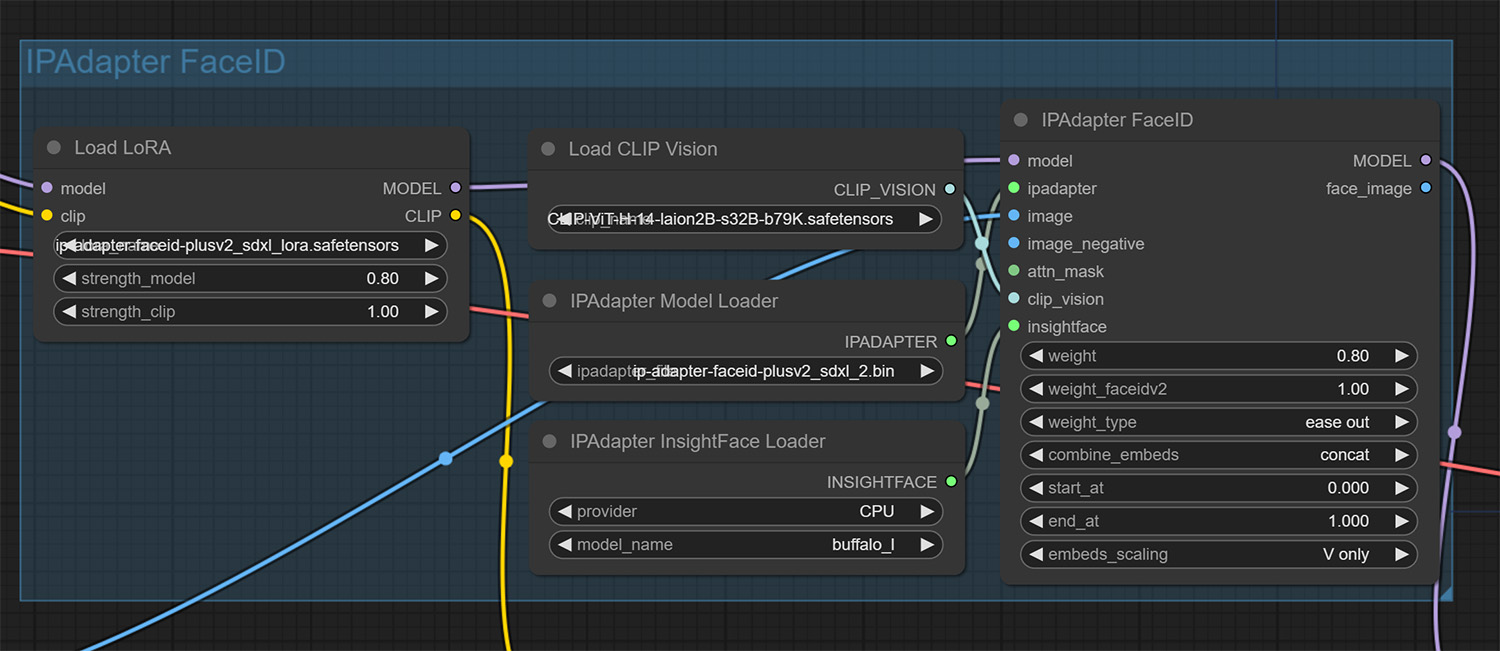
首先可以确定的是,为了保持用户特征,IP-Adapter FaceID 是我们的核心模块。
The first thing that can be determined is that in order to maintain user characteristics, IP-Adapter FaceID is our core module.
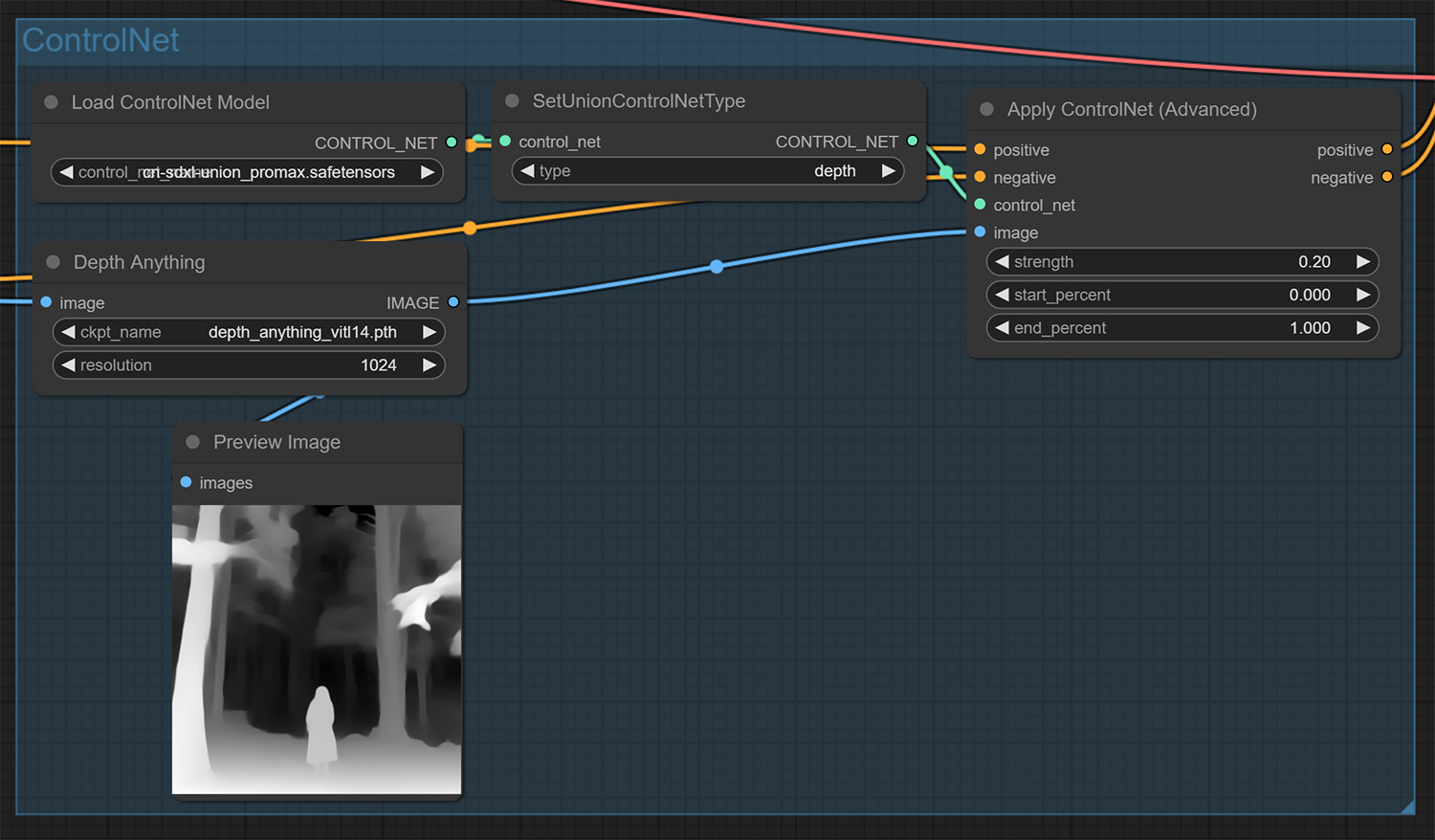
其次,ControlNet 也必不可少,因为我们要保持和原图的位置关系。但是,由于折纸艺术的风格化很明显,保留人像图的过多真实细节是不合适的,因此我仅使用深度图作为控制条件,且权重非常低。
Secondly, ControlNet is also essential because we want to maintain the positional relationship with the original image. However, since the stylization of origami art is so strong, it is inappropriate to reserve realistic details of the original image, so I only use the depth map as a control condition with a very low weight.
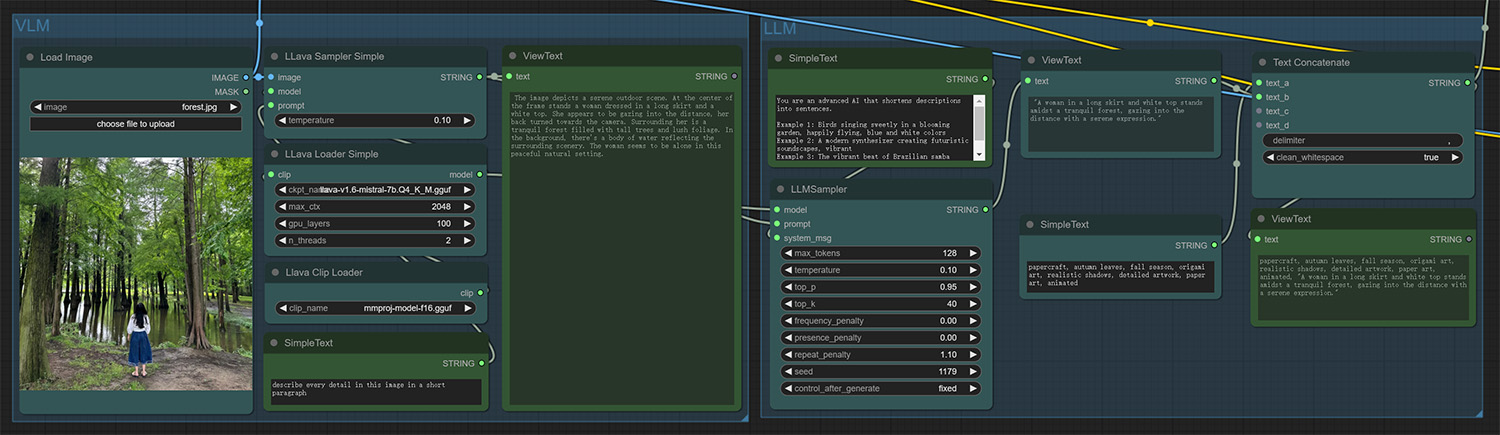
考虑到我们不可能为每个用户上传的图片都人工写提示词,我们使用VLM来提取关键信息。需要注意的是,LLM输出的提示词不应该带有任何风格描述,因为我们需要手动输入一段提示词作为所有生成图的风格。
Considering that we are unable to manually write prompts for each image uploaded by the user, we use VLM to extract patterns. It should be noted that the prompts output by LLM should not have any style description, because we manually input a sentence about origami style for all generations.
最后,我们再添加一个IP-Adapter模块的风格迁移,来加深生成图的折纸感。
Finally, we add another IP-Adapter module to transfer style, thus deepen the origami feel of the generated image.
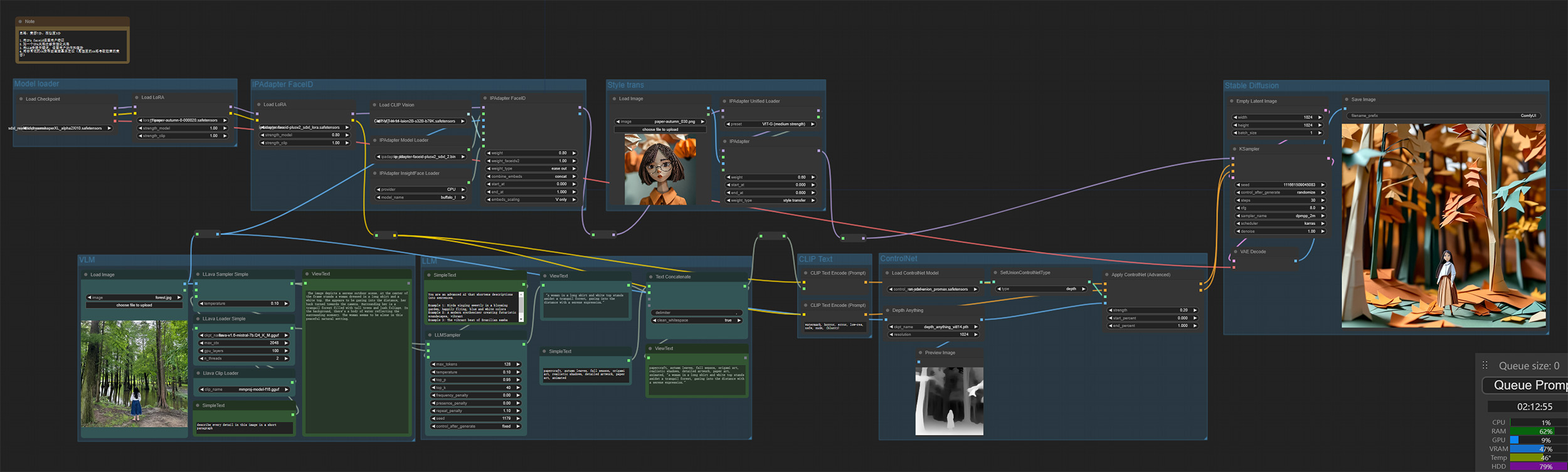
效果展示 Results








